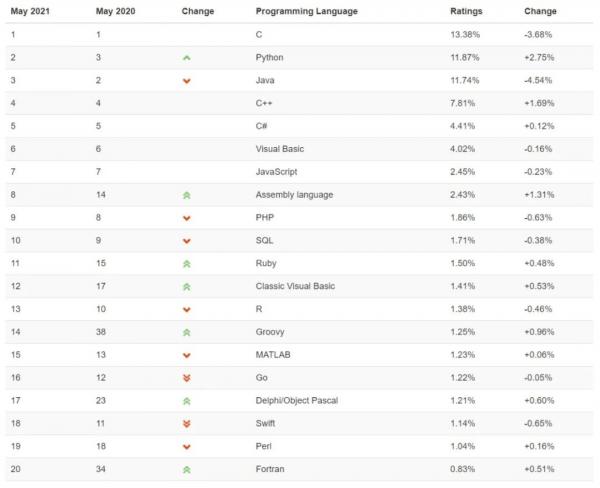
09月22日, 2014 155次
根源:华章高科技
正文引见以次排序算法:
冒泡排序(bubble sort)
合并排序(merge sort)

插入排序(insertion sort)

希尔排序(shell sort)

采用排序(selection sort)
01 在Python中调换变量
在实行排序和搜索算法时,须要调换两个变量的值。在Python中,有一种大略的本领不妨调换两个变量,如次所示:
var1 = 1var2 = 2var1,var2 = var2,var1print(var1,var2)
咱们看看调换的截止。
2 1
正文的一切排序算法中都运用这种大略的本领来调换变量值。

底下咱们从冒泡排序发端进修。
02 冒泡排序
冒泡排序是一切排序算法中最大略且最慢的一种算法,其安排办法是:当算法迭代时使得列表中的最大值像气泡一律冒到列表的尾部。因为其最坏功夫搀杂度是O(N2),如前所述,它该当用来较小的数据集。
领会冒泡排序背地的论理
冒泡排序鉴于百般迭代(称为遍历)。对于巨细为N的列表,冒泡排序将会举行N–1轮遍历。咱们提防计划第一次迭代,也即是第一轮遍历。
第一轮遍历的目的是将最大值挪动到列表的尾部。第一轮遍历实行时,咱们将看到列表中的最大值冒到了尾部。

冒泡排序会比拟两个相邻变量的值,即使较低场所的变量值大于较高场所的变量值,则调换这两个值。这种迭代从来连接到咱们达到列表的结束,如图3-2所示。

▲图 3-2
此刻,咱们看看怎样运用Python实行冒泡排序:
#Pass 1 of Bubble SortlastElementIndex = len(list)-1print(0,list)for idx in range(lastElementIndex):if list[idx] list[idx+1]:list[idx],list[idx+1]=list[idx+1],list[idx]print(idx+1,list)
在Python中实行冒泡排序的第一轮遍历后,截止如图3-3所示。
▲图 3-3
一旦第一轮遍历实行,最大值就仍旧坐落列表的尾部。算法接下来将举行第二轮遍历,第二轮遍历的目的是将第二大的值挪动到列表第二高的场所。为此,算法将再次比拟相邻变量的值,即使它们未依照巨细陈设则举行调换。第二轮遍历将跳过列表顶部元素,由于该元素在第一轮遍历后仍旧被放在了精确的场所上,所以不须要再挪动。
实行第二轮遍历后,算法将连接实行第三轮车遍历,以该类推,直到列表中的一切数据都依照叶序陈设。该算法将须要N–1轮遍历本领将巨细为N的列表实足排序。Python中冒泡排序的完备实行如次所示。
def BubbleSort(list):# Excahnge the elements to arrange in orderlastElementIndex = len(list)-1for passNo in range(lastElementIndex,0,-1):for idx in range(passNo):if list[idx] list[idx+1]:list[idx],list[idx+1]=list[idx+1],list[idx]return list
此刻,咱们看看冒泡排序算法的本能。
冒泡排序的本能
很简单就不妨看出冒泡排序包括了两层轮回:
外层轮回:外层轮回称为遍历。比方,第一轮遍历即是外层轮回的第一次迭代。
内层轮回:在历次内层轮回的迭代进程中,对列表中结余的未排序元素举行排序,直到最高值冒泡到右侧为止。第一轮遍历将举行N–1次比拟,第二轮遍历将举行N–2次比拟,而每轮后续遍历将缩小一次比拟操纵。
因为生存两层轮回,最坏情景下的运转时搀杂度是O(n2)。

03 插入排序
插入排序的基础思维是,在历次迭代中,城市从数据会合移除一个数据点,而后将其插入到精确的场所,这即是干什么将其称为插入排序算法。
在第一次迭代中,咱们采用两个数据点,并对它们举行排序,而后夸大采用范畴,采用第三个数据点,并按照其值找到精确的场所。该算法从来举行到一切的数据点都被挪动到精确的场所。这个进程如图3-5所示。
▲图 3-5
插入排序算法的Python代码如次所示:
def InsertionSort(list):for i in range(1, len(list)):j = i-1element_next = list[i]while (list[j] element_next) and (j = 0):list[j+1] = list[j]j=j-1list[j+1] = element_nextreturn list
请提防,在主轮回中,咱们在所有列表中举行遍历。在历次迭代中,两个相邻的元素辨别是list[j](暂时元素)和list[i](下一个元素)。
在list[j] element_next且j =0时,咱们会将暂时元素与下一个元素举行比拟。
咱们运用此代码对数组举行排序。
list = [25,26,22,24,27,23,21]InsertionSort(list)print(list)
截止:
[21,22,23,24,25,26,27]
咱们看一下插入排序算法的本能。
从算法的刻画中不妨鲜明看出,即使数据集仍旧排好序,那么插入排序将实行得特殊快。究竟上,即使数据集仍旧排好序,则插入排序仅需线性运转功夫,即O(n)。最蹩脚的情景是,历次内层轮回都要挪动列表中的一切元素。即使内层轮回由i设置,则插入排序算法的最坏功夫搀杂度由以次公式给出:
总的遍历度数如图3-7所示。

▲图 3-7
普遍来说,插入排序不妨用在袖珍数据集上。对于较大的数据集,因为其平衡本能为平方级,不倡导运用插入排序。
04 合并排序
到暂时为止,咱们仍旧引见了两种排序算法:冒泡排序和插入排序。即使数据是局部无序的,那么它们的本能都比拟好。正文计划的第三种算法是合并排序算法,它是由约翰·冯·诺依曼(John von Neumann)在20世纪40岁月开拓的。该算法的重要特性是,其本能不在于于输出数据能否已排序。
同MapReduce和其余大数据算法一律,合并排序算法也是鉴于礼治战略而安排的。在被称为分别的第一阶段中,算法将数据递归地分红两局部,直到数据的范围小于设置的阈值。在被称为合并的第二阶段中,算法连接地举行合并和处置,直到获得最后的截止。该算法的论理如图3-8所示。
▲图 3-8
咱们先来看看合并排序算法的伪代码:
不妨看到,该算法有以次三个办法:
它将列表分别为两个长度十分的局部。
它运用递返来举行分别,直到每个列表的长度为1。
它将无序的局部合并成一个无序的列表并归来。
合并排序算法的实行代码如次所示。
def MergeSort(list):if len(list) 1:mid = len(list)//2 #splits list in halfleft = list[:mid]right = list[mid:]MergeSort(left) #repeats until length of each list is 1MergeSort(right)a = 0b = 0c = 0while a len(left) and b len(right):if left[a] right[b]:list[c]=left[a]a = a + 1else:list[c]=right[b]b = b + 1c = c + 1while a len(left):list[c]=left[a]a = a + 1c = c + 1while b len(right):list[c]=right[b]b = b + 1c = c + 1return list
运转前方的Python代码时,会爆发一个对应的输入截止,如次所示。
list = [44,16,83,7,67,21,34,45,10]MergeSort(list)print(list)[7, 10, 16, 21, 34, 44, 45, 67, 83]
不妨看到,该代码实行后的输入截止是一个无序列表。
05 希尔排序
冒泡排序算法比拟相邻的元素,即使它们不适合程序,则举行调换。即使咱们有一个局部无序的列表,则冒泡排序该当不妨给出比拟有理的本能,由于一旦轮回中不复爆发元素调换,冒泡排序就会退出。
然而对于一个范围为N的实足无序的列表,冒泡排序必需过程N–1次完备的迭代本领获得实足排好序的列表。
丹诺德·希尔(Donald Shell)提出了希尔排序(以他的名字定名),该算法置疑了对采用相邻的元素举行比拟和调换的需要性。
此刻,咱们来领会这个观念。
在第一轮遍历中,咱们不采用相邻的元素,而是采用有恒定间距的两个元素,最后排序出由一对数据点构成的子列表,如图3-11所示。在第二轮遍历中,对包括四个数据点的子列表举行排序(见图3-11)。

▲图 3-11
在后续的遍历中,每个子列表中的数据点数目连接减少,子列表的数目连接缩小,直到只剩下一个包括一切数据点的子列表为止。此时,咱们不妨觉得列表仍旧排好序了。
在Python中,用来实行希尔排序算法的代码如次:
def ShellSort(list):distance = len(list) // 2while distance 0:for i in range(distance, len(list)):temp = list[i]j = i# Sort the sub list for this distancewhile j = distance and list[j - distance] temp:list[j] = list[j - distance]j = j-distancelist[j] = temp# Reduce the distance for the next elementdistance = distance//2return list
用前方的代码对列表举行排序,截止如次所示。
list = [26,17,20,11,23,21,13,18,24,14,12,22,16,15,19,25]ShellSort(list)print(list)[11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]

不妨看到,挪用ShellSort因变量胜利地对输出数组举行了排序。
希尔排序的本能
希尔排序并不实用于大数据集,它用来中型数据集。大概地讲,它在一个最多有6000个元素的列表上有十分好的本能,即使数据的局部程序精确,则本能会更好。在最佳的情景下,即使一个列表仍旧排好序,则它只须要遍历一次N个元从来考证程序,进而爆发O(N)的最好本能。
06 采用排序
正如在正文前方所看到的,冒泡排序是最大略的排序算法。采用排序是对冒泡排序的矫正,咱们试图使得算法所需的总调换度数最小化。
与冒泡排序算法的N–1轮遍历进程比拟,采用排序在每轮遍历中仅爆发一次调换,在每轮遍历中探求最大值并将其径直挪动到尾部,而不是像冒泡排序那么,每轮遍历都一步一步地将最大的值向尾部挪动。所以,在第一轮遍历后,最大值坐落列表尾部。在第二轮遍历后,第二大的值会紧邻最大值。
跟着算法的举行,反面的值将按照它们的巨细挪动到精确的场所。结果一个值将在第N–1轮遍历后挪动。所以,采用排序同样须要N–1轮遍历本领对N个数据项举行排序(如图3-13所示)。
▲图 3-13
这边展现了采用排序在Python中的实行:
def SelectionSort(list):for fill_slot in range(len(list) - 1, 0, -1):max_index = 0for location in range(1, fill_slot + 1):if list[location] list[max_index]:max_index = locationlist[fill_slot],list[max_index] = list[max_index],list[fill_slot]return list
实行采用排序算法时,将爆发如次所示的输入。
list = [70,15,25,19,34,44]SelectionSort(list)print(list)[15,19,25,34,44,70]
不妨看到,结果的输入截止即是排好序的列表。
采用排序的本能
采用排序的最坏功夫搀杂度是O(N2)。请提防,其最坏本能好像于冒泡排序的本能,所以不该当用来对较大的数据集举行排序。然而,采用排序仍是比冒泡排序安排更好的算法,因为调换度数缩小,其平衡搀杂度比冒泡排序好。

总结:采用一种排序算法
适合地采用排序算法既在于于暂时输出数据的范围,也在于于暂时输出数据的状况。对于仍旧排好序的较小的输出列表,运用高档算法会给代码带来不需要的搀杂度,而本能的提高不妨忽视不计。
比方,对于较小的数据集,咱们不须要运用合并排序,冒泡排序更简单领会和实行。即使数据仍旧被局部排好序了,则不妨运用插入排序。对于较大的数据集,合并排序算法是最佳的采用。
正文摘编自《步调员必会的40种算法》,经出书方受权颁布。
蔓延观赏《步调员必会的40种算法》
引荐语:该书全力于运用算法求解本质题目,扶助入门者领会算法背地的论理和数学常识。该书实质充分,波及算法普通、安排本领、领会本领、排序算法、搜索算法、图算法、线性筹备算法、呆板进修算法、引荐算法、数据算法、暗号算法和并行算法等实质,中心报告怎样运用Python举行算法实行和算法本能的比拟与领会。